
正则表达式的拆分
对于一门语言的掌握程度怎么样,可以有两个角度来衡量:读和写。
不仅要求自己能解决问题,还要看懂别人的解决方案。代码是这样,正则表达式也是这样。
正则这门语言跟其他语言有一点不同,它通常就是一大堆字符,而没有所谓“语句”的概念。
如何能正确地把一大串正则拆分成一块一块的,成为了破解“天书”的关键
本章内容
结构和操作符
注意要点
案例分析
结构和操作符
编程语言一般都有操作符。只要有操作符,就会出现一个问题。当一大堆操作在一起时,先操作谁,又后操作谁呢?为了不产生歧义,就需要语言本身定义好操作顺序,即所谓的优先级。
而在正则表达式中,操作符都体现在结构中,即由特殊字符和普通字符所代表的一个个特殊整体。
JavaScript 正则表达式中,都有哪些结构呢?
字符字面量、字符组、量词、锚、分组、选择分支、反向引用。
具体含义简要回顾如下:
| 结构 | 说明 |
|---|---|
| 字面量 | 匹配一个具体字符,包括不用转义的和需要转义的比如a匹配"a".又比如\n匹配换行符,又比如\.匹配小数点 |
| 字符组 | 匹配一个字符,可以事多种可能之一.比如[0-9]表示匹配一个数字.也有\d的简写形式.另外还有反义字符组比如[^0-9]表示一个非数字字符,也有\D的简写形式 |
| 量词 | 表示一个字符连续出现,比如a{1,3}表示"a"字符连续出现 3 次,另外还有常见的简写形式.比如a+表示 a 字符出现至少一次 |
| 锚点 | 匹配一个位置,而不是字符。比如^匹配字符串的开头,又比如\b匹配单词边界,又比如(?=\d)表示字符前面的位置 |
| 分组 | 用括号表示一个整体,比如(ab)+表示"ab"两个字符连续出现多次,也可以用非捕获分组(?:ab)+ |
| 分支 | 多个子表达式多选一,比如abc|bcd表达式匹配"abc"或者"bcd"字符字串。反向引用,比如\2表示引用第二个分组 |
其中涉及到的操作符有:
| 操作符描述 | 操作符 | 优先级 |
|---|---|---|
| 转义符 | \ | 1 |
| 括号和方括号 | (...),(?:...),(?=...),(?!...),[...] | 2 |
| 量词限定符 | {m},{m,n},{m,},?,*,+ | 3 |
| 位置和序列 | ^,$,\元字符,一般字符 | 4 |
| 管道符(竖杠) | | | 5 |
上面操作符的优先级 由上到下,由高到低
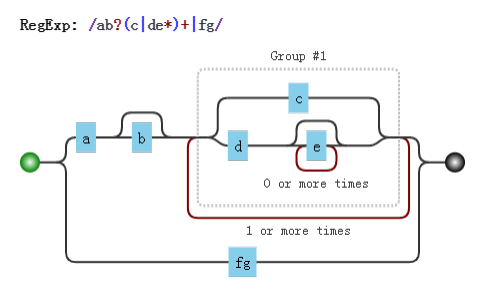
这里,我们来分析一个正则:
/ab?(c|de*)+|fg/由于括号的存在,所以
(c|de*)是一个整体结构在
(c|de*)其中注意其中的量词,因此 e 是一个整体结构又因为分支结构
|优先级最低,因此c事一个整体,而de*是另外一个整体同理,整个正则分成了,
a,b?,(...)+,f,g由于分支的原因,又可以分成ab?(c|de*)+和fg这两部分
上面的例子可用可视化分析如下:
注意要点
匹配字符串整体问题
因为要是匹配整个字符串,我们经常会在正则前后加上锚 ^和$
比如要匹配目标字符串abc或者bcd的时候,如果一不小心就会写成 /^abc|bcd$/
而位置字符和字符序列优先级要比竖杠高,故其匹配的结构是:
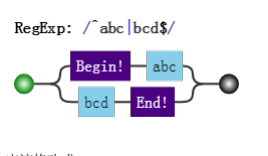
应该修改成:
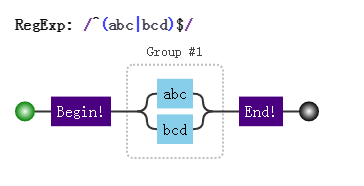
量词连缀问题
假设 要匹配这样的字符串:
每个字符为
a,b,c任选其一字符串的长度是 3 的倍数
此时 正则不能想当然的写成 /^[abc]{3}+$/,这样会报错,说+前面没有什么可重复的
因此要修改成:
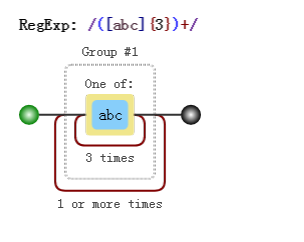
元字符转义问题
所谓元字符就是正则中有特殊含义的字符
所有结构里,用到的元字符总结如下:
^、$、.、*、+、?、|、\、/、(、)、[、]、{、}、=、!、:、- ,当匹配上面的字符本身时,可以一律转义:
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /\^\$\.\*\+\?\|\\\/\[\]\{\}\=\!\:\-\,/;
console.log(regex.test(string));
// => true其中string中的\字符也要转义的
另外在string中,也可以把每个字符转义,当然转义后的结果仍是本身;
var string = "^$.*+?|\\/[]{}=!:-,";
var string2 = "^$.*+?|\\/[]{}=!:-,";
console.log(string == string2);
// => true现在的问题是,是不是每个字符都需要转义呢?否,看情况。
字符组中的元字符
跟字符组相关的元字符有 [、]、^、-。因此在会引起歧义的地方进行转义。例如开头的 ^ 必须转义,不然 会把整个字符组,看成反义字符组。
var string = "^$.*+?|\\/[]{}=!:-,";
var regex = /[\^$.*+?|\\/\[\]{}=!:\-,]/g;
console.log( string.match(regex) );
// => ["^", "$", ".", "*", "+", "?", "|", "\", "/", "[", "]", "{", "}", "=", "!", ":",
"-", ","]匹配 "[abc]" 和 "{3,5}"
我们知道 [abc],是个字符组。如果要匹配字符串 "[abc]" 时,该怎么办? 可以写成 /[abc]/,也可以写成 /[abc]/,测试如下:
var string = "[abc]";
var regex = /\[abc]/g;
console.log(string.match(regex)[0]);
// => "[abc]"只需要在第一个方括号转义即可,因为后面的方括号构不成字符组,正则不会引发歧义,自然不需要转义。
同理,要匹配字符串 "{3,5}",只需要把正则写成 /{3,5}/ 即可。
另外,我们知道量词有简写形式 {m,},却没有 {,n} 的情况。虽然后者不构成量词的形式,但此时并不会报 错。当然,匹配的字符串也是 "{,n}",测试如下:
var string = "{,3}";
var regex = /{,3}/g;
console.log(string.match(regex)[0]);
// => "{,3}"其余情况
比如 =、!、:、-、, 等符号,只要不在特殊结构中,并不需要转义。
但是,括号需要前后都转义的,如 /(123)/。
至于剩下的 ^、$、.、*、+、?、|、\、/ 等字符,只要不在字符组内,都需要转义的。
案例分析
身份证
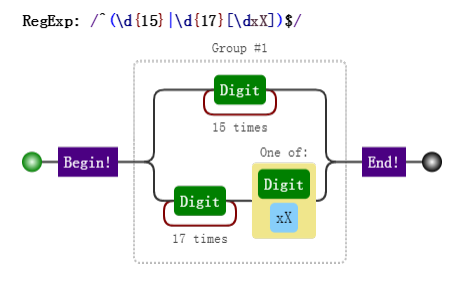
正则表达式:
/^(\d{15}|\d{17}[\dxX])$/;因为竖杠 | 的优先级最低,所以正则分成了两部分 \d{15} 和 \d{17}[\dxX]。
\d{15} 表示 15 位连续数字。
\d{17}[\dxX] 表示 17 位连续数字,最后一位可以是数字,可以大小写字母 "x"。
可视化如下:
IPV4 地址
正则表达式
/^((0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])\.){3}(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])$/这个正则,看起来非常吓人。但是熟悉优先级后,会立马得出如下的结构:
((…)\.){3}(…)其中,两个 (…) 是一样的结构。表示匹配的是 3 位数字。因此整个结构是
然后再来分析 (…):
(0{0,2}\d|0?\d{2}|1\d{2}|2[0-4]\d|25[0-5])
它是一个多选结构,分成 5 个部分:
0{0,2}\d,匹配一位数,包括 "0" 补齐的。比如,"9"、"09"、"009";
0?\d{2},匹配两位数,包括 "0" 补齐的,也包括一位数;
1\d{2},匹配 "100" 到 "199";
2[0-4]\d,匹配 "200" 到 "249";
25[0-5],匹配 "250" 到 "255"。
最后来看一下其可视化形式:
